现状
截至目前(2024/04/12),rvv on valgrind的状态
- 支持nulgrind和memcheck两种tool
- 支持除了floating-piont和fixed-point之外的所有rvv指令
- 可以用来跑autovectorized coremark等应用
- 部分rvv memcheck的逻辑有改进的地方
- 如有需要,可以支持完整rvv指令,即使有些地方是不完美的
最新代码库在
- repo - https://github.com/intel/valgrind-rvv
- branch - poc-rvv-remove-vl-from-ir
Valgrind背景知识
实现逻辑
- valgrind有一套中间表达IR
- guest code和instrumentation code比如memcheck都会先用IR表达,然后IR最后会翻译成host指令。
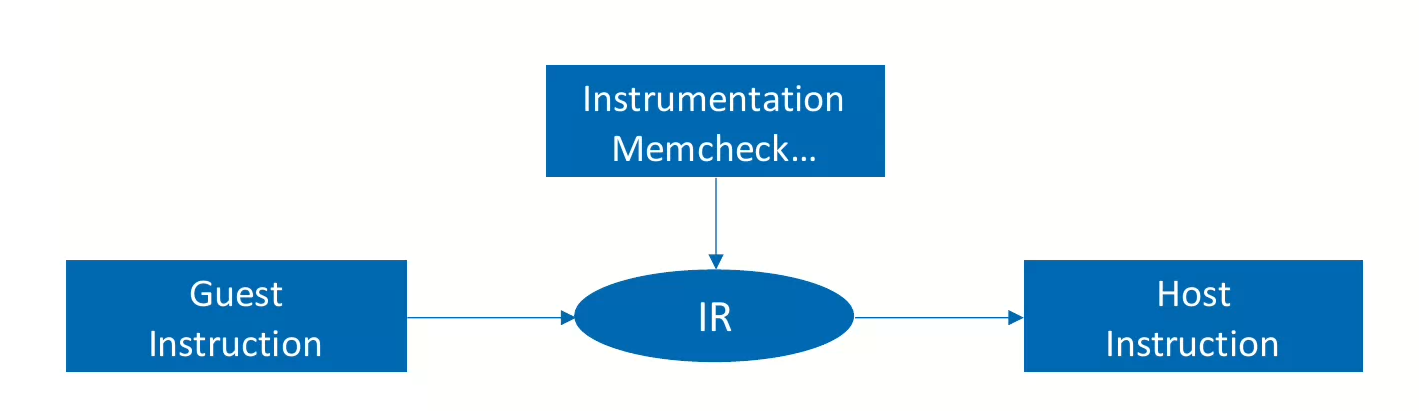
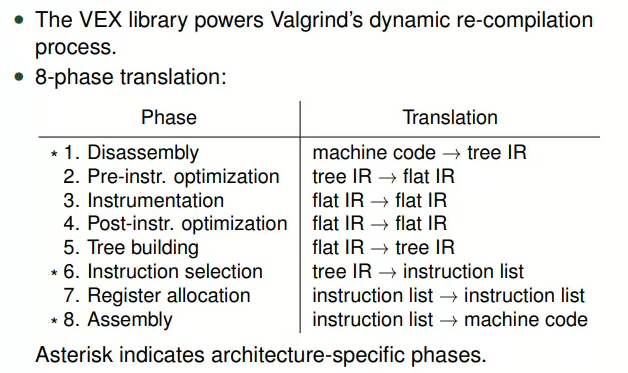
总共会经历这么几个步骤,下图来源于[1]
代码逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
LibvEX_Translate
irsb = LibvEx_FrontEnd(vta, &res, &pxControl);
disInstrFn = RISCV64FN(disInstr_RISCV64);
irsb = bb_to_IR(vta->guest_extents, disInstrFn, ...);
switch (INSN(1, 0))
case 0b11:
dres->len = inst_size = 4;
ok = dis_RISCV64_standard(dres, irsb, insn, ...);
irsb = do_iropt_BB(irsb, specHelper, preciseMemExnsFn, *pxControl, ...);
irsb = vta->instrument1(vta->callback_opaque, irsb);
irsb = vta->instrument2(vta->callback_opaque, irsb);
irsb = cprop_BB(irsb);
Libvex_BackEnd(vta, &res, irsb, pxControl);
switch (vta->arch_host) {
case VexArchRISCV64:
iselSB = RISCV64FN(iselSB_RISCV64);
emit = CAST_TO_TYPEOF(emit)RISCV64FN(emit_RISCV64Instr);
iselSB
for (i = 0; i < bb->stmts_used; i++)
iselstmt(env, bb->stmts[i]);
switch (stmt->tag)
case Ist_store:
if (tyd == Ity_I64) addInstr(env, RISCV64Instr_Store(RISCV64op_SD, src, addr, 0));
RISCV64Instr* i = LibVEX_Alloc_inline(sizeof(RISCV64Instr));
i->tag = RISCV64in_Store;
i->RISCV64in.Store.op = op;
for (i = 0; i < rcode->arr_used; i++)
emit
switch (i->tag) {
case RISCV64in_MV:
Int dst = iregEnc(i->RISCV64in.MV.dst)
UInt src = iregEnc(i->RISCV64in.MV.src)
p = emit_CR(p, 0b10, src, dst, 0b1000);
Ushort the_insn = 0;
the_insn |= opcode << 0;
the_insn |= rs2 << 2;
the_insn |= rd << 7;
the_insn |= funct4 << 12;
return emit16(p, the_insn);
Memcheck逻辑
- Valid-value (V) bits
In short, each bit in the system has (conceptually) an associated V bit, which follows it around everywhere, even inside the CPU. Yes, all the CPU’s registers (integer, floating point, vector and condition registers) have their own V bit vectors.
- Valid-address (A) bits
all bytes in memory, but not in the CPU, have an associated valid-address (A) bit. This indicates whether or not the program can legitimately read or write that location.
RVV支持
增加普通指令
在valgrind里面增加指令一般有如下方法, 很明显前面的更好。
- existing lops (IR)
- creating a new lop
- a clean helper
- a dirty helper
增加RVV指令
首先已有的ir是支持不了rvv的,所以退而求其次,只能选择new ir。不到非不得已不会选择helper实现,helper会导致instrumentation不好做。
实现难点
- rvv是第一个在valgrind支持的variable length的ISA,没有参考实现
- valgrind默认ir都是固定大小,但是对于rvv却不是,这些新isa的加入打破了原来valgrind的一些假设
- 因为rvv引入了大量新的ir,这些ir的memcheck逻辑都需要重写,本身memcheck针对scalar的ir逻辑就比较复杂,对于部分vector指令就更加复杂
- rvv有lmul等概念,从而寄存器(组)的大小是可变的,导致后端的寄存器分配变得复杂
- rvv指令很多,实现工作量大,目前在后端通过一种机制来尽量复用qemu的代码,同时也解决上面寄存器分配的问题,虽然理论性能会有所下降
- 社区想使用统一的ir给rvv以及arm sve共享,又增加了复杂度,是不是必须这样做我持保留态度。valgrind mailing list有相关讨论,也是目前block的主要原因
- vector load/store的实现,如果拆成scalar一个个是操作,vlen太长的话会导致生成的ir过长从而破外valgrind原来的假设都需要处理,如果不拆的话怎么保证memcheck的逻辑
- 还有一些实现的细节也需要慢慢改进,比如struct VexGuestRISCV64State的大小约束了vlen的长度,虽然不是大问题,但都需要一个个解决