最近在sophgo上测试了Linux内核6.1和6.6的性能,发现riscv上syscall的性能有超过10%以上的下降,可以看到指令数明显。
测试用例
为了缩小debug的范围,我们选取最简单的getpid进行分析,而不是混合了unixbench里面使用了多个系统调用的syscall本身。
$ ./syscall 10 getpid
找到commit
对于这个问题,做个perf record基本上就能找到问题所在,两个版本的调用栈差异很容易看出来。
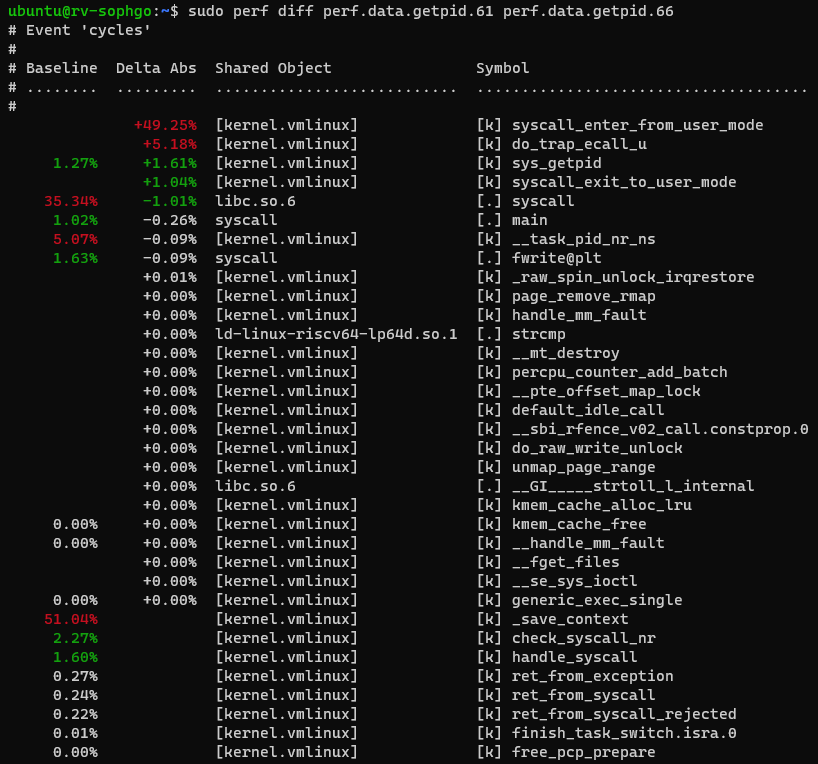
顺着路径可以找到这个commit
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
commit f0bddf50586da81360627a772be0e355b62f071e
Author: Guo Ren <guoren@kernel.org>
Date: Tue Feb 21 22:30:18 2023 -0500
riscv: entry: Convert to generic entry
This patch converts riscv to use the generic entry infrastructure from
kernel/entry/*. The generic entry makes maintainers' work easier and
codes more elegant. Here are the changes:
- More clear entry.S with handle_exception and ret_from_exception
- Get rid of complex custom signal implementation
- Move syscall procedure from assembly to C, which is much more
readable.
- Connect ret_from_fork & ret_from_kernel_thread to generic entry.
- Wrap with irqentry_enter/exit and syscall_enter/exit_from_user_mode
- Use the standard preemption code instead of custom
相当于通过性能获取代码可读性, 可以认为是合理的tradeoff,当然从性能角度确实引起了regression。
Qemu验证
在qemu上进行验证主要是比较方便,除非有bug内核上每一个commit对应的kernel都能在qemu上跑起来,而sophgo并没有upstream,所以想测试某个commit都需要做移植。
使用之前提到的在 qemu上获取guest动态指令数 的方法
$ ./qemu_icount_bpf.sh $(pgrep qemu)
在这个commit上的测试结果如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
root@ubuntu:/home/ubuntu/unixbench/UnixBench/pgms# ./syscall 10 getpid
COUNT|11470019|1|lps
time: 336064384105596, dur: 1000245152, count: 286363445
time: 336065384452093, dur: 1000346438, count: 286269548
time: 336066384676652, dur: 1000224470, count: 286837560
time: 336067384708991, dur: 1000032305, count: 286651941
time: 336068384710012, dur: 1000001072, count: 286916535
time: 336069384710378, dur: 1000000408, count: 287129672
time: 336070385795133, dur: 1001084623, count: 287359137
time: 336071386161965, dur: 1000366660, count: 287168792
time: 336072386616986, dur: 1000452866, count: 224648083
time: 336073388062117, dur: 1001444274, count: 234536
time: 336074389954081, dur: 1001890246, count: 298929
总共做了3个版本的测试,汇总如下
| commit | instructions per syscall |
|---|---|
| d0db02c6 (right before the change) | ~200 |
| f0bddf50 (the change) | ~250 |
| ffd2cb6b (latest upstream) | ~250 |
后续
虽然为了可读性做tradeoff是可以理解的,在保持可读性的同时还是可能有一些优化空间的,比如这几个patch,但在上面的测试中并没有反应出来,需要后续继续分析。
1
2
3
4
5
6
7
8
9
10
11
12
commit d68019471995ba47e56a9da355df13a1cdb5bf7e
Author: Sven Schnelle <svens@linux.ibm.com>
Date: Mon Dec 18 08:45:18 2023 +0100
entry: Move exit to usermode functions to header file
To allow inlining, move exit_to_user_mode() to
entry-common.h.
Signed-off-by: Sven Schnelle <svens@linux.ibm.com>
Signed-off-by: Thomas Gleixner <tglx@linutronix.de>
Link: https://lore.kernel.org/r/20231218074520.1998026-2-svens@linux.ibm.com